AI video localisation tools have become much easier to use, but ease of use is not the same as quality at scale. We often hear from clients who are confident creating the first video in their own language, but less sure what will happen when that content is translated and regenerated across multiple markets.
That concern is understandable. Without in-house language expertise, it can be difficult to judge whether the translation is accurate, whether the terminology is right or whether the final result still feels on-brand. And while it is easy to scale a video into 10+ languages, any errors introduced early in the workflow can spread just as quickly.
That’s why the workflow matters. Tools like HeyGen, Synthesia, VEED and ElevenLabs may appear to offer similar headline features, but they differ in how they handle translation, editing and regeneration. Those differences affect quality, consistency and how well a project scales – and there are also privacy factors to consider.
Read on to learn which factors matter most when creating multilingual lip-synced videos using such platforms.
Key terms explained
XLIFF: a standard file format used in professional translation workflows. It allows translators work on text in a structured way outside the video platform, making review, revision and handoff easier across larger multilingual projects.
Processor: a company presenting itself as acting mainly like a data processor rather than using customer data more broadly for its own purposes
A script is the source text you intended to say before recording.
A transcript is the text the platform derives from what was actually said in the finished audio or video. If you are dubbing (replacing the existing audio recording with a new voice – usually in another language) an already-recorded video, the transcript becomes the operational source text for translation.
ASR: automatic speech recognition. The technology that turns spoken audio into written text for review, translation or voice generation. For further details, see our article on key questions to ask your language service provider).
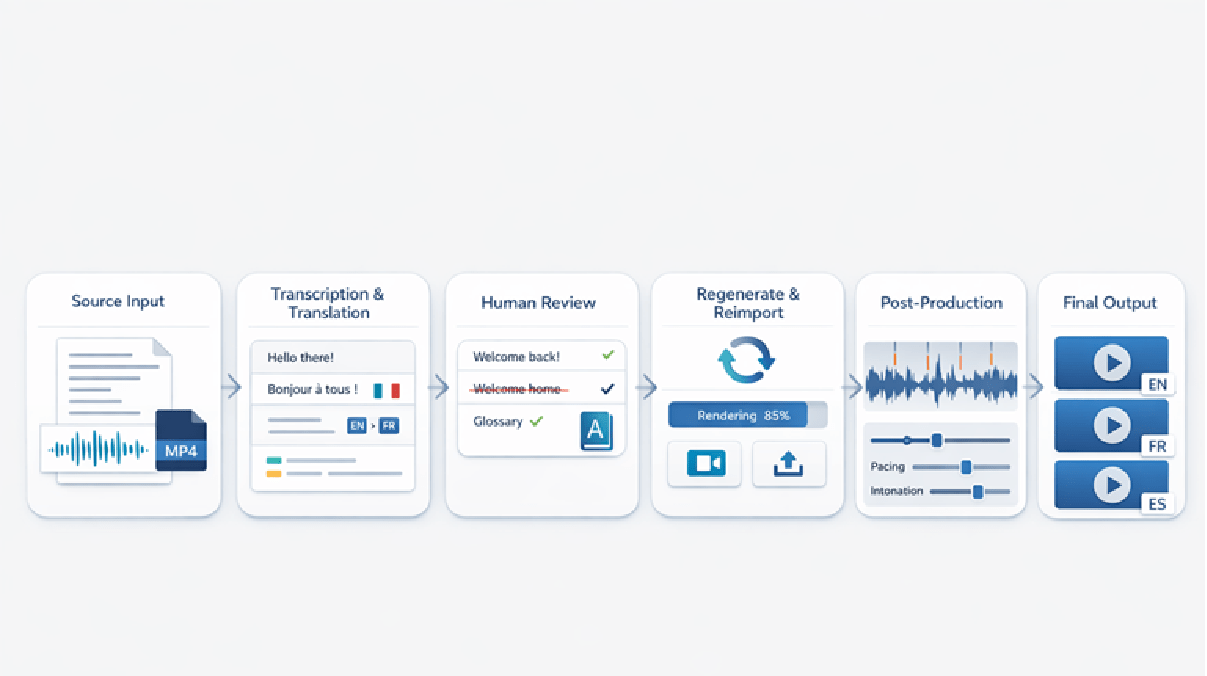
The workflow
The clearest way to compare these platforms is to look at where translation actually happens in a typical workflow. In practice, there are three primary AI video transcription and localisation workflows: script-based, audio-based and video-based. Each has different implications for automated transcription and translation, human-refined content and the amount of post-production needed.
Stage 1 – source preparation and generation
- Script-based workflow: prepare the source-language script, refine it if needed, and generate the source video directly from that approved script.
- Audio-based workflow: start from recorded audio rather than a finished script, use ASR to produce a transcript, review and correct that transcript, then use it as the basis for the final video output – whether through dubbing, lip-sync or avatar generation.
- Video-based workflow: upload a finished video, use ASR to derive the transcript from what was actually said, then review, correct and, where necessary, partially or fully regenerate content before translation.
Stage 2 – localisation, regeneration and post-production
- Run the initial AI video translation or dubbing pass
- Review and edit the translated script or transcript as human-refined content
- Reimport or regenerate the updated version
- Fine-tune lip-sync, timing, pacing and intonation in post-production
- Repeat this iterative process until the localised version feels natural and usable
The sequence matters, and there is often a gap between the ideal workflow and the real-world workflow.
In an ideal scenario, the translation team is involved before any AI video generation takes place. In a script-based workflow, that means refining and approving the source script early, then translating it before the AI generates localised outputs. This usually gives the best control over terminology, tone and structure because the language team is working from stable source text rather than cleaning up errors later.
In the real world, however, customers often rely on AI-translated transcripts generated from recorded audio or finished video. In audio-based and video-based workflows, the platform may be working from ASR output rather than an approved script, so the transcript becomes the operational source text for translation.
At that point, localisation becomes an iterative process: generate the AI video translation, edit it, reimport or regenerate it, then fine-tune lip-sync, timing and natural flow in post-production. This is also where the language professional can add value by adjusting pacing, suggesting pauses, checking intonation and spotting where the target-language wording no longer fits the original timing. Many platforms primarily map translations onto the original timeline and may offer speech compression or slight speed increases to make the audio fit. That can help technically, but if pushed too far it may sound unnatural. The issue becomes even more visible with text expansion: languages such as French or German can easily run 20 to 30 percent longer than English, which affects duration, timing and readability and often needs careful handling during post-production rather than simple automatic compression.
Here’s an example:
Text expansion
English: Our new platform helps teams create multilingual training videos faster.
German: Unsere neue Plattform hilft Teams dabei, mehrsprachige Schulungsvideos schneller zu erstellen.
How the platforms compare
Before we look specifically at translation quality, we compare the four platforms at an operational level: how their workflows differ, where the strongest quality-control checkpoints sit, what that means when you scale, and what privacy or policy considerations may come into play.
All four platforms use some combination of: speech recognition/transcription > machine (AI) translation > synthetic voice generation > timing or lip-sync alignment > subtitle and export layers.
However, the order, editability and tightness of integration differ. Some tools:
- are avatar-native, meaning script, voice, lip movement and output are tightly linked
- are subtitle- or transcript-first
- are voice-first, with lip-sync added later
- allow a strong human review checkpoint before generation, while others put more emphasis on fast automatic output first and manual cleanup second
That distinction becomes more important when you move from three test languages to twenty or thirty production languages, because small terminology errors, pace mismatches and lip-sync artefacts scale with you.
Overview of how the platforms differ when you scale multilingual video
| Platform | Translation model approach | Best control point for quality | Scaling implication | Background and gesture alteration | Policy snapshot (June 2026) |
| HeyGen | ASR + translation + voice preservation + lip-sync, with Speed/Precision modes, glossary rules, subtitles and Proofread / Review & Edit. | Review translated script before final generation; glossary control is especially valuable for terminology-heavy content. | Strong for scaling presenter-led videos into many markets without losing voice identity, but full lip-sync quality still depends on the input video and mode selected. | Great for lip-synced localisation; deeper gesture/background control comes when you rebuild as an avatar video.
|
Publicly says no training on user content, but privacy policy includes broader model-improvement language. |
| Synthesia | Transcript-first dubbing + XLIFF translation + optional lip-sync + timing control for generated or uploaded video | Transcript correction and XLIFF-based review before dubbing/generation. | Best fit for enterprise-style multilingual operations where repeatability, external review and governance matter more than one-click novelty. | Best for controlled avatar videos and enterprise localisation; original dubbed footage is not re-choreographed.
|
The platform presents customer data as remaining under a processor relationship, with processing limited to the customer’s instructions.
. |
| VEED | Modular pipeline: subtitles/transcripts, translation, AI dubbing, optional lip-sync/video remapping. | Transcript/subtitle editing is the main QA checkpoint. | Flexible and cost-effective, but teams scaling to many languages will usually need more structured editorial QA than with avatar-native systems. | Most “surgical” of the four for uploaded real video: it changes the mouth and audio, not the whole performance.
|
Free tier still allows model-training use of uploaded content; paid tiers are better suited to business use. |
| ElevenLabs | Voice-first dubbing: transcription, translation, speaker separation, voice-preserving regeneration, clip/timeline editing; lip-sync now exists but is secondary to the audio workflow. | Clip-level transcript/translation editing and regeneration. | Excellent when voice identity and emotional continuity matter most; less natively “video-operational” than full avatar platforms. | Voice-first with added lip-sync; more visual changes come when you move from dubbing into fresh image/video generation.
|
Non-enterprise users must opt out if they do not want data used for model improvement; enterprise defaults are stronger. |
Alongside workflow, editability and translation quality, there’s one more factor worth checking when choosing a platform: how it handles voice, face and identity-linked data.
This is important because some AI voice and avatar workflows may involve biometric or other sensitive personal data, depending on how the platform processes voiceprints, facial geometry, verification footage or custom avatar inputs. In other words, if a tool is not just translating content but also reconstructing a voice, animating a face or verifying a person’s likeness, the compliance question becomes broader than simple text processing.
So where does professional translation or review fit best?
The best place for professional translation or review is not at the very end of the process but at the points where errors can still be corrected before they spread. In practice, that means reviewing the source transcript after ASR where relevant, checking the translated text before final dubbing or regeneration, and then carrying out post-production review of the finished localised video. That final stage is not just a language check: it is where timing, intonation, natural flow and pacing can be improved, pauses can be introduced where needed and awkward results caused by speech compression or text expansion can be identified and corrected. It matters because once a mistranscription (the speaker says “crowd-based funding”, but the ASR understands it as “cloud-based funding”), mistranslation or timing problem enters the workflow, it can be repeated across every language version.
Across all four platforms, AI translation is often good enough to accelerate multilingual production, but not reliable enough to publish unattended when brand tone, specialist terminology or audience trust matter.
What should be reviewed, and why a glossary is not enough
A brand glossary is helpful, but it only solves part of the problem. It can improve consistency for approved terms, product names and recurring phrases, but it does not verify whether the transcript is accurate, whether the sentence means what the speaker intended, whether the tone fits the market or whether lip-sync and timing constraints have forced unnatural wording. A glossary helps with approved terminology, but it does not solve the wider issue of context. AI translation may use the right term at sentence level while still missing intended meaning, tone, audience nuance or the purpose of the message as a whole. That’s why human review (referred to as human in the loop or HITL) still adds value at several levels: checking the source transcript against the original script or recording, reviewing translated text for meaning and tone before regeneration, and sense-checking the final video in context. The more specialist, regulated or brand-sensitive the content is, the more important those checkpoints become.
Ready to scale, with confidence?
AI voice and video tools can genuinely accelerate multilingual content production, but one-click output still needs careful review. If you’d like support choosing the right workflow, review points and language setup for your content, we’d be happy to help.
