AI is changing not just what we produce but how we produce it. One of the clearest examples is vibe coding: an AI-first approach to building software where you describe what you want in natural language and let the system generate the code. The emphasis shifts from writing every line manually to guiding, testing and refining the result.
That makes vibe coding a useful lens for understanding AI translation. In both cases, AI turns human language into a usable output: in one, a working application; in the other, a target-language text.
The process is faster and more accessible, but the same tension remains: machine output can be fluent and convincing while still missing the point. For a non-expert user, that creates a particular risk: The translation may look finished, yet they have no real way of judging whether it is accurate, effective or fit for purpose.
What is vibe coding?
Vibe coding is an AI-assisted way of building software by describing what you want in natural language and letting the system generate the code. The term, popularised by AI researcher Andrej Karpathy in 2025, captures a broader shift: instead of writing every line manually, you guide the process through prompts, testing and iteration. The role of the human changes too. Rather than acting mainly as the coder, you act more like the director of the workflow.
- Describe what you want
- Let the AI generate code
- Test the output
- Refine through further prompts
The appeal is speed and accessibility. Non-developers can build working prototypes quickly, and experienced teams can move from idea to testable product far faster than before. But the trade-offs are real: AI-generated code can introduce vulnerabilities, maintenance problems and technical debt – where you move fast at the outset and deal with the consequences later – if nobody reviews it properly. In short, the workflow becomes faster, but expertise is still essential.
Giving clear instructions before giving in to the vibe is key in AI translation
AI translation systems, including both neural machine translation (NMT) and large language model (LLM)-based translation, work in broadly similar ways. Instead of translating word by word, modern systems process whole sentences and wider context to generate more fluent output. That’s why the results often read far more naturally than older forms of machine translation which followed an isolated sentence-by-sentence approach.
Like vibe coding, AI translation is powerful but incomplete. It can produce fast, fluent drafts, but it is less dependable when success depends on nuance, tone, audience awareness or specialist context. That is why human review still matters: not because the output is always bad, but because subtle errors can be expensive to miss.
The real shift is from accepting fluent-sounding output to shaping it with judgement. Some drafts need only light post-editing; others require substantial rewriting (see our article on light vs heavy copy-editing). Either way, the value lies in knowing what to keep, what to fix and what to question.
With OpenAI’s shift to more proactive and agentic AI systems, it means human judgement and the ability to work effectively alongside increasingly proactive AI systems will become even more valuable.
Does AI understand?
At a basic level, the system maps the source text into an internal representation and generates a target-language version from it. It does not understand in the way a person does, but it models patterns in language well enough to produce convincing results at speed.
A key strength of these systems is contextual prediction. A word like bank will be interpreted differently depending on whether the surrounding text suggests finance, geography or something else. That context-sensitivity is what makes modern AI translation feel more fluent and scalable than earlier rule-based or phrase-based systems.
Output quality still depends heavily on the model and the data behind it. Different systems make different assumptions about tone, terminology and what counts as the most likely translation, so results can vary widely. Because training data is always historical, models may also handle new terminology, recent events or shifting usage unevenly.
The parallel: translating intent
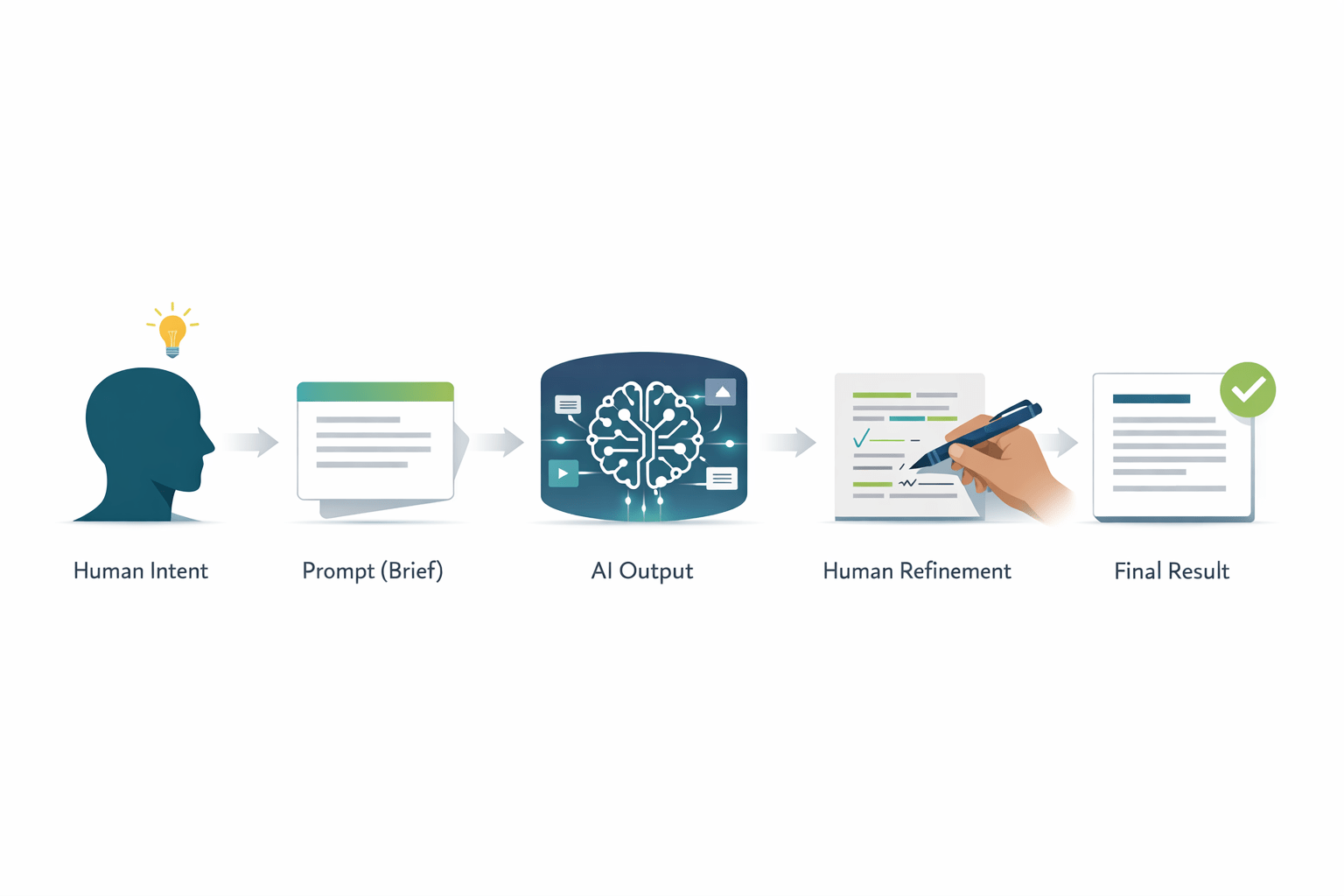
The comparison becomes clearer when both workflows are treated as systems for translating intent. The inputs differ, but the pattern is strikingly similar: a person provides language, the AI generates a draft output, and an expert decides whether that output is actually fit for purpose.
1. Natural language becomes the interface
Both workflows begin with language rather than manual construction.
- In vibe coding, you describe the functionality you want and the AI turns it into code.
- In AI translation, you provide a detailed brief together with the source text and the AI turns it into target-language output.
In both cases, language becomes the instruction layer for generating something more structured.
2. The human role shifts from producing to directing
Expertise doesn’t disappear; it moves upstream and downstream in the workflow. In AI translation, the brief plays the same role that prompting and specification play in vibe coding: it frames the task, sets the constraints and gives the system a better chance of producing something worth refining.
- In software, developers increasingly guide, test and refine AI-generated code instead of writing every line themselves.
- In translation, linguists review, correct and improve AI-generated drafts instead of translating every sentence from scratch.
The task changes from creating everything manually to judging whether the machine-generated result does the job.
That shift also changes the translator’s cognitive effort. Instead of building the text from scratch, they must stay alert to subtle errors, weak phrasing and false confidence in output that often looks finished before it has really been understood or validated.
With a clear brief, some AI output may only need light post-editing; but when the draft is context-blind, misleading or commercially weak, the output will need heavy post-editing – and that’s where the apparent time savings begin to disappear.
3. Informed iteration is where quality emerges
Neither system reliably gets it right in a single pass. In both workflows, the first output is a draft, not a finished result. What matters is not just repetition, but informed iteration. Subject expertise helps people spot weak assumptions, resolve ambiguity quickly and avoid wasting time on endless reworking.
Vibe coding follows a loop of prompt → generate → test → refine. AI translation follows a comparable loop of brief + source text → translate → review → revise. In both cases, quality comes from feedback and correction rather than from the first output alone.
4. AI is strongest at scale and weakest at nuance
Both systems excel at producing large volumes of output quickly. Both are less reliable when meaning depends on subtle judgement.
But both systems struggle with subtlety:
- In software, weak prompts or unclear requirements can produce code that looks plausible but fails in practice.
- In translation, missing context can produce text that sounds fluent but misses tone, intent, terminology or cultural fit.
AI can recognise patterns in language, but nuance often depends on what is implied rather than stated, and on human judgement shaped by context and lived experience.
Where AI translation creates risk for clients
For clients, one of the biggest risks is assuming AI translation will work well on any content without preparation. The missing step is the brief. Too often, people paste text into a chatbot with nothing more than “translate this” and assume the result is ready to use.
That is where problems begin. Output may look finished while still being inaccurate, misleading or unfit for purpose. In practice, results depend on the guidance the system is given, the quality of the source content and whether the output is reviewed by someone who understands the market, the audience and the purpose of the text.
When those steps are skipped, problems often only become visible after publication, when fixing them is slower, more expensive and more disruptive.
Take a business localising a large volume of website, product or support content. AI can generate usable (in a narrow set of circumstances) draft translations in seconds, which is attractive when speed and scale matter. But fluent output is not the same as effective communication, especially if nobody checks whether the language still fits the brand, the sector and the target audience.
This is where the commercial risk appears: content may look polished enough to publish while quietly losing persuasive force, clarity or compliance value – or worse: the output could be completely wrong because the training data was incorrect or too limited.
Typical issues include:
- Calls to action lose their persuasive tone
- Brand voice becomes neutral or inconsistent
- Cultural references become inaccurate or lose their relevance
- Register slips into a safe middle ground or shifts inconsistently
- Use of non-industry-standard terminology and phrasing
- Weak training data can produce invented or unsupported translations
A common pattern is that the wording is technically correct but commercially weaker. A campaign line may be translated literally, yet lose the action, urgency or emotional pull that made it effective in the source language. The message survives, but the impact does not.
AI can translate what something says, but not always what it is trying to do.
This is where human expertise becomes critical, shaping the work so it achieves its intended effect in each target market.
Translation debt: when speed creates downstream cost
In software, technical debt describes the cost of moving fast now and fixing the consequences later. AI translation can create a similar problem. It can reduce turnaround time dramatically, but if content is pushed through without the right source preparation, terminology control or review, the savings are often offset by corrections further downstream.
That translation debt can show up in many ways: inconsistent terminology across markets, brand voice erosion, extra in-country review, delayed approvals, rework after publication or content that technically reads well but performs poorly. The problem is not speed itself; it is speed without enough quality control around it.
The way to avoid it is not to reject AI, but to use it within a defined workflow. Clear source content, approved terminology, appropriate model choice and expert review all act as guardrails. Used well, AI helps organisations scale multilingual content faster. Used carelessly, it simply moves the cost to a later stage, where fixing it is slower and more expensive and can take longer than translating properly in the first place.
Key differences
Despite these parallels, software and translation are not the same kind of task.
- In software, success is often easier to test. Code may still contain hidden weaknesses, but there are usually clearer ways to verify whether it functions as intended.
- In translation, success is less binary. A text can be grammatically correct and still fail because the tone is wrong, the terminology is weak or the message does not land with the intended audience.
That changes the nature of risk.
- In software, AI errors may lead to bugs, vulnerabilities or maintenance problems.
- In translation, AI errors may lead to misunderstanding, brand dilution, compliance issues or lost commercial impact.
That’s why translation requires not just accuracy, but judgement about effect, audience and purpose.
What AI in translation means for businesses
For organisations, the key question is not whether to use AI translation, but where it fits best and where human expertise needs to stay closely involved.
- Use AI translation where speed, scale and first-draft efficiency matter.
- Keep human review close to content that carries brand, legal, regulatory, technical or commercial risk.
- Treat source quality, review workflow and market context as part of the translation process, not as optional extras.
The strongest results usually come from combining both: AI for speed and throughput, and expert review for accuracy, tone, consistency and market fit.
The future: human–AI collaboration where AI drafts and people craft
In both coding and translation, the emerging model is collaboration. AI generates; people evaluate, refine and take responsibility for the result. But that only works if the human role is clearly understood.
- In vibe coding, poor prompts or insufficient testing can lead to hidden security and maintenance risks.
- In AI translation, missing context or lack of review can result in output that is fluent – but incorrect, misleading or culturally inappropriate.
The expertise is still needed; it just operates at a different level.
Less effort may go into producing the first draft, but more goes into checking whether the result is accurate, appropriate and ready to use.
When AI turns intent into output
Vibe coding may have started as a meme, but it points to a deeper shift. Across domains, AI is increasingly being used to turn human intent into usable output: in software, into code; in translation, into meaning.
That’s powerful, but it also changes where value sits.
For businesses working across languages, the value is no longer just in producing text quickly. It lies in making sure that text does what it is supposed to do: persuade, guide, inform or protect, in every language and for every audience.
The real challenge is not whether to adopt AI translation, but how to apply it well, with the right workflow, the right oversight and the right expectations. It’s something we can help with.
